
目录
- 面对混乱的医学文本,一个用海量真实世界数据「喂」大的新 AI 模型 MedTE,在一套全新的、极其严苛的「医学 NLP 联考」中,证明了通用 AI 在医学领域就是个门外汉。
- 通过将分子对接建模成一场蛋白和配体相互适应的「博弈游戏」,一种新算法在柔性对接这个老大难问题上,实现了速度和精度的双重提升。
- 一个名为 Uni-Mol3 的全新基础模型,通过教 AI‘读懂’分子的三维语言,试图将充满玄学的有机反应预测,变成一门更严谨的计算科学。
1. AI 读懂病历?先过了这套新考卷
我们都试过,把一段临床试验报告或者电子病历扔给那些声称无所不能的通用大语言模型,然后得到一堆看起来像那么回事,但仔细一琢磨全是废话的答案。为什么?因为医学是一门有自己独特语言、语法甚至「黑话」的学科。
通用 AI 在浩瀚的互联网上学习,它可能读过维基百科的词条,但它没在凌晨三点的急诊室里待过。它不知道「SOB」在这里是「呼吸急促」(shortness of breath),而不是别的什么意思。它更分不清一种药物的商品名、化学名和内部代号。所以,直接用它们来处理严肃的医学数据,结果往往是灾难性的。
一些早期的医学专用模型,比如 BioBERT,算是迈出了正确的一步,但它们像是只读教科书的医学生,饮食太「干净」了,主要吃的都是 PubMed 摘要这类格式规整的文本。
MedTE 的研究者给模型准备的「食谱」极其丰盛且真实。除了 PubMed、维基百科、ClinicalTrials.gov 这些相对干净的数据,他们还把 MIMIC-IV 数据库里那些充满了缩写、术语、甚至医生个人习惯用语的真实临床笔记,也一并扔了进去。让 AI 在信息的泥潭里打滚,它才能学会游泳。
学习方法也很关键。他们用的是「自监督对比学习」。这方法说白了,就是不停地给模型出判断题。比如,拿两段文本给它看,告诉它:「这两段都提到了药物 A 用于治疗肺癌,所以它们在语义上是‘近’的。」再拿另外两段:「这段是讲心脏搭桥的,那段是讲糖尿病的,所以它们是‘远’的。」经过数百万次这样的训练,模型的大脑里就逐渐形成了一张有意义的、符合医学逻辑的语义地图。
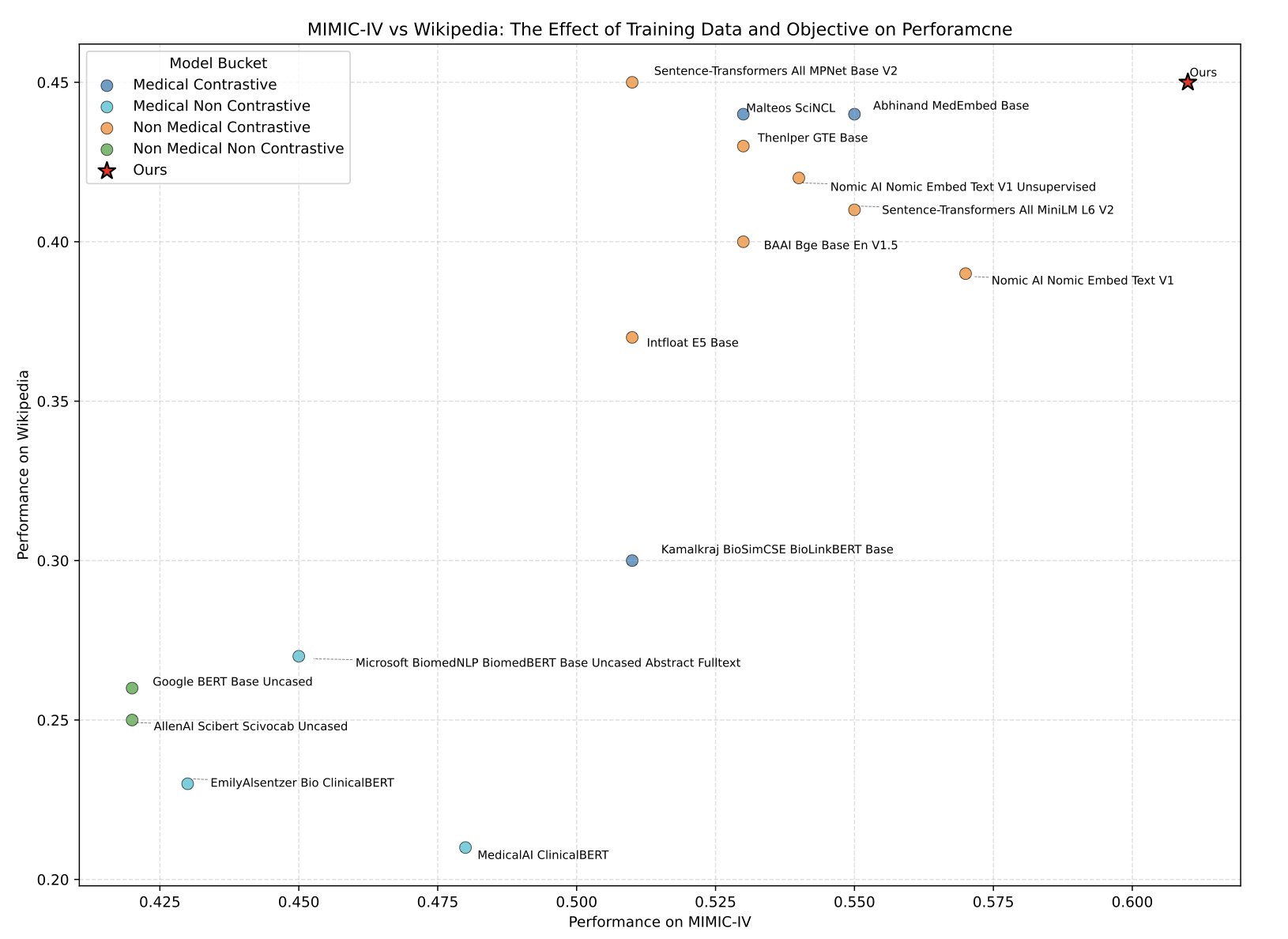
研究者没有王婆卖瓜。他们不仅发布了模型,还打造了一套全新的「医疗 NLP 联合能力测试」——MedTEB。这可不是什么简单的选择题,而是包含 51 项不同任务的综合性基准,从文本分类、聚类,到关系判断、信息检索,应有尽有。这相当于他们不仅培养出了一个优等生,还顺手制定了这门课的期末考试标准。
结果毫无悬念,MedTE 在这套考卷上把之前的各种模型都甩在了身后。
我们终于有了一个更可靠的工具,可以用来挖掘那些沉睡在海量文本数据里的金矿。无论是从电子病历里筛选符合特定标准的患者,还是从数万份临床试验报告里寻找药物不良反应的蛛丝马迹,一个真正「懂行」的 AI,都能让效率发生质的飞跃。
📜Paper: https://arxiv.org/abs/2507.19407
💻Code: https://github.com/MohammadKhodadad/MedTE
2. 分子对接新博弈:让蛋白和配体对打
分子对接,搞药的人真是对它又爱又恨。几十年来,它一直是我们工具箱里的基石,但我们也都心知肚明,它有多不靠谱。尤其是在处理「柔性对接」时——也就是蛋白质的口袋和配体分子都能自由活动的情况。这就像试图把一把不断扭动的钥匙,插进一把同样在晃动的锁里,纯粹是场噩梦。
大部分现有的 AI 对接模型,都试图用一个大而全的神经网络,去同时理解钥匙和锁。但问题是,钥匙(小分子)和锁(蛋白质口袋)的复杂度和物理性质天差地别。用同一个模型去硬解,就像让一个举重选手去跑马拉松,总感觉哪里不对劲。
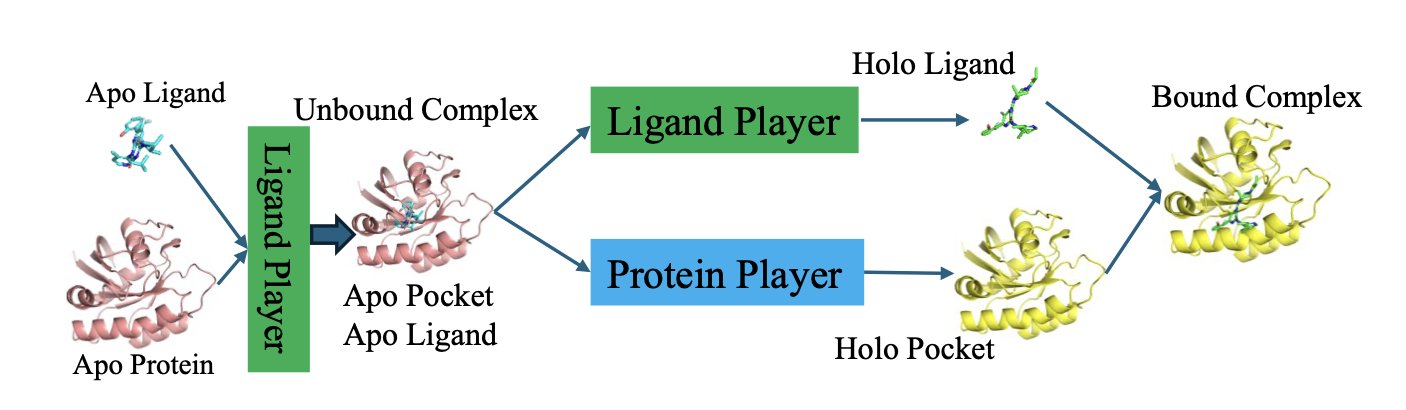
但这篇 arXiv 上的新论文,提出了脑洞大开的玩法——「对接游戏」(The Docking Game)。他们不把这看成一个单纯的优化问题,而是把它看成一场博弈。
在这场游戏里,有两个玩家:
1. 配体玩家 :一个专门负责预测小分子最佳构象的 AI 模型。
2. 蛋白玩家 :另一个专门负责预测口袋侧链如何响应配体的 AI 模型。
游戏怎么玩?通过一个叫「循环自博弈」(LoopPlay)的算法。这个过程就像两个高手在过招,不断试探和适应对方。
首先,配体玩家先出招:「我看我摆成这个构象不错。」然后把这个构象信息告诉蛋白玩家。
蛋白玩家看了看,回应道:「哦?你要这么躺着?那我口袋里的这个苯丙氨酸就得这么转一下,才能更好地契合你。」然后,它把自己调整后的口袋构象,再反馈给配体玩家。
配体玩家拿到这个新信息,心想:「原来口袋会这么变啊,那我原来的构象可能不是最优的,我得再调整一下。」
就这样,它们在一个外循环里来回传递信息,互相适应。同时,在各自的内循环里,它们还会进行「自我修炼」,不断优化自己的预测能力。这个过程一直持续,直到双方都觉得再也无法单方面做出更好的调整了——也就是达到了所谓的「纳什均衡」。在这个点上,它们找到了一个彼此都最舒服的结合模式。
这个思路承认了蛋白和配体的差异,并为它们各自配备了「专家系统」。这让整个学习过程更有针对性,也更符合物理现实。
结果证明,这个新玩法确实有效。论文报告说,在预测准确的结合模式上,它的性能比之前的 SOTA 方法提升了大约 10%。在分子对接这个已经相当成熟的领域,10% 的提升绝对是一个值得关注的数字。更棒的是,它的速度还飞快,平均每对分子只需要 0.32 秒。这意味着它完全可以用于大规模的虚拟筛选。
3. AI 读懂分子 3D 语言,破解化学反应
AI 预测化学反应一直是个听起来很美,但用起来糟心的东西。
大多数现有模型,都还活在二维世界里。它们靠读取 SMILES 字符串来理解分子——这就像试图通过阅读一份零件清单来理解一台发动机是如何运转的。它知道有哪些零件,但对它们如何空间排布、如何相互啮合一无所知。
而化学反应的精髓,恰恰就在于三维空间里的那场电子云的舞蹈。哪个亲核试剂从哪个角度进攻,哪个离去基团会从哪边离开,这些都由立体化学决定。只看二维,就是瞎子摸象。
Uni-Mol3 直面问题的本质:化学是三维的。
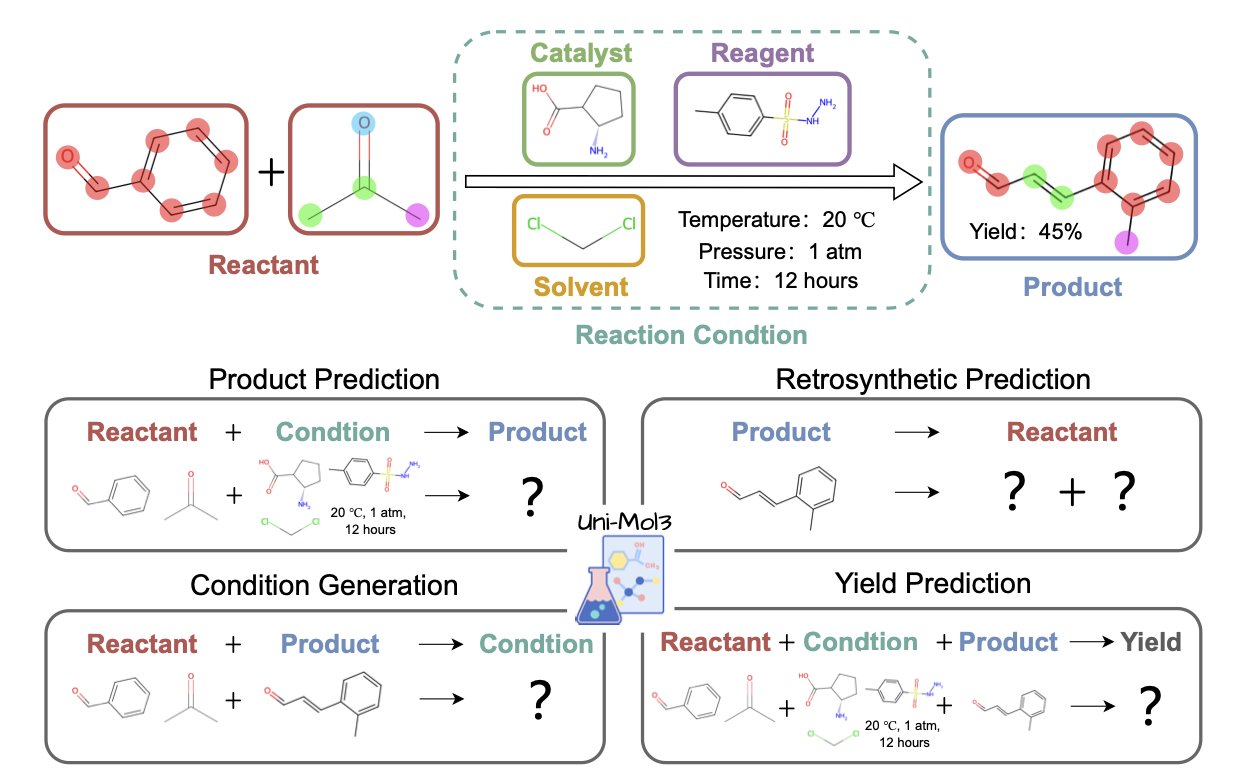
Uni-Mol3 的核心是一个叫「分子令牌化器」(Mol-Tokenizer)的东西。它把分子的三维结构,连同其他物理化学性质一起,翻译成了一种 AI 能理解的「分子语言」。它不再是读「C-C-O-H」这样的字母,而是直接学习分子的空间形状、电荷分布这些真正决定反应性的东西。这就让 AI 第一次戴上了「3D 眼镜」去看待化学反应。
它的训练方法也很有章法,分两步走。第一步,先进行「分子预训练」,让模型先学会「单词」——也就是单个分子的语法规则和内在逻辑。第二步,再进行「反应预训练」,让模型开始学习「句子」——也就是多个分子相遇时,会发生什么样的故事,遵循什么样的反应规律。
这个「先学单词,再学语法」的策略,让 Uni-Mol3 在一系列化学家最关心的任务上,表现得像个老手。你给它反应物和试剂,它能预测出主要产物,而且是对立体化学有感知的预测;你给它一个复杂的目标分子,它能像个资深合成化学家一样,给出几条靠谱的逆合成路线;更离谱的是,它还能对反应条件(用什么催化剂、什么溶剂)和最终的产率给出一个八九不离十的猜测。
这意味着我们未来或许不用再盲目地去筛选几十种反应条件,而是可以先让 AI 给我们一个 shortlist。这意味着在设计一个全新的合成路线时,我们有了一个不知疲倦、博览群书的助手来提供灵感。
当然它的预测仍然需要经验丰富的人去判断,更需要在实验室里用双手去验证。但它无疑是一个威力巨大的新工具。它把化学反应的计算模拟,从二维的「简笔画」时代,真正带入了三维的「高清建模」时代。
📜Paper: https://arxiv.org/abs/2508.00920