
目录
- 只要经过严格筛选,用 AI 预测的「假」结构数据来训练结合亲和力模型,效果居然不比用珍贵的「真」实验数据差,这为药物发现打开了一扇新的大门。
- 生成式 AI 是个想象力爆棚但毫无纪律的实习生,这篇综述讲的就是我们如何用强化学习等多重「紧箍咒」,逼它从胡乱涂鸦变成设计真正有用的药物分子。
aiXiv平台通过构建一个由 AI 自主提交、审稿和修改的闭环系统,试图解决 AI 生成科研内容无法融入传统出版体系的难题,但目前仍是模拟环境下的概念验证。
1. AI 造数据喂 AI:药物发现的新范式?
在结构为基础的药物发现(SBDD)领域,我们所有人都面临一个共同的痛点:高质量的、带有亲和力数据的蛋白 - 配体复合物晶体结构,实在是太少了。我们的很多机器学习模型,就像是嗷嗷待哺的婴儿,却一直被「数据饥荒」饿得面黄肌瘦。
于是,一个诱人的想法出现了:既然 AlphaFold 这类 AI 模型能预测结构,我们能不能让它给我们「造」一些数据出来,管它叫「合成数据」也好,「假数据」也罢,只要管够就行。这听起来像是个完美的解决方案,对吧?无限的数据,无限的可能。
但这里面有个巨大的陷阱,那就是「垃圾进,垃圾出」。
一个糟糕的结合构象,对训练一个亲和力模型来说,其破坏力远大于没有数据。它会彻底误导模型,让它学到一堆错误的物理化学知识。
这篇论文回答了一个关键的问题:这些 AI 造的数据,到底能不能用?怎么用?
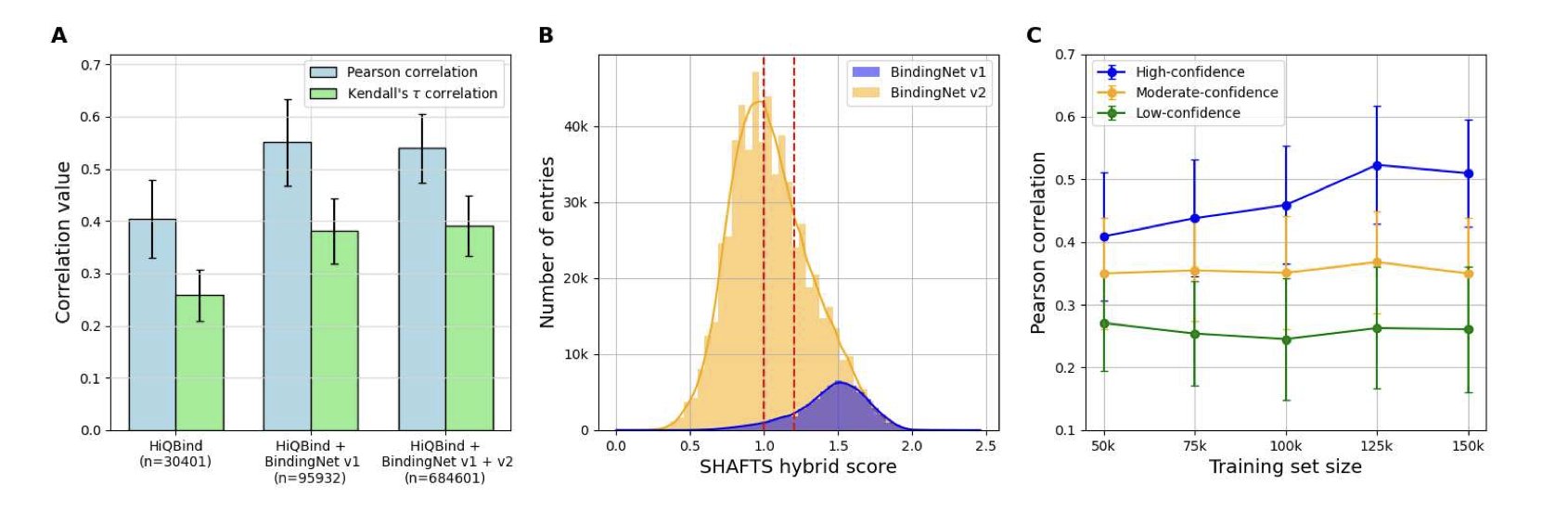
研究者们用一个叫 Boltz-1x 的共折叠模型生成了大量的蛋白 - 配体复合物结构,然后用这些结构去训练一个结合亲和力打分函数。他们发现直接把所有 AI 生成的结构不管三七二十一扔进去训练,效果很烂。模型的性能提升非常有限。
真正的魔法发生在「筛选」这一步。
他们建立了一套简单粗暴但行之有效的筛选规则:
1. 优先选择单链复合物(这通常意味着更简单的体系,AI 预测起来更靠谱)。
2. 只保留那些模型自己都觉得「很有把握」的预测结果,具体来说,就是 Boltz-1x 置信度分数高于 0.9 的。
3. 确保训练集和测试集之间有一定的相似性,避免模型去预测完全未知的化学空间。
当他们用这套「严选」出来的、高质量的合成数据去训练模型时,奇迹发生了。新模型的性能,与那个只用宝贵的 PDBbind 实验数据训练出来的模型相比,几乎没有差别。
我们终于有了一套可行的流程,来为那些缺乏实验数据的靶点家族(比如大量的孤儿受体、GPCR)构建可靠的打分函数。我们不再完全受制于晶体学家的产出速度。我们可以主动出击,为我们感兴趣的任何靶点,生成可用的训练数据。
这并不是说实验数据不重要了,恰恰相反,它依然是金标准。但这篇工作给了我们一个强大的「数据放大器」。它告诉我们,如何用少量的「真」知识,去指导 AI 生成大量的、可信的「衍生知识」。
📜Title: Can AI-predicted complexes teach machine learning to compute drug binding affinity?
📜Paper: https://arxiv.org/abs/2507.07882
💻Code: https://github.com/wehs7661/AEV-PLIG-refined
2. AI 制药:想象力需要缰绳
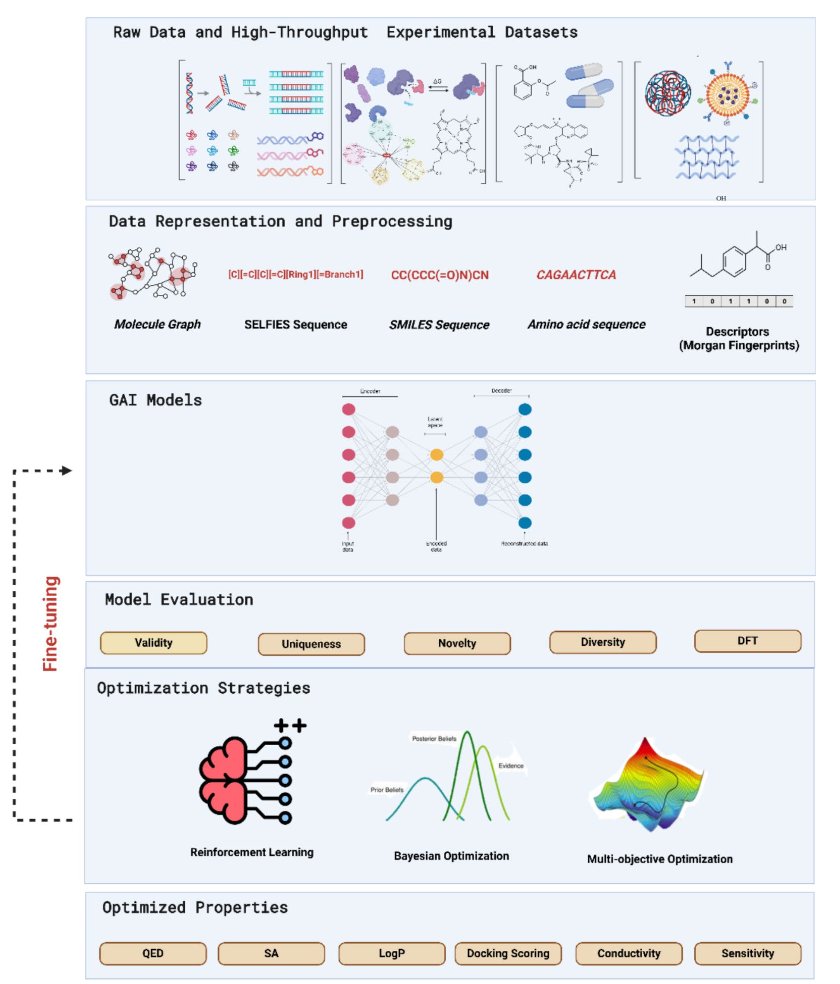
生成式 AI(GenAI)在药物发现领域,就像一个精力无限、想象力爆棚的实习生。你给他看几百万个分子,他就能通宵达旦地给你画出几亿个新的来。听起来很棒,对吧?但问题是,如果你不给他任何指导,他画出来的东西,99% 都是一堆没用的、甚至化学上根本不存在的涂鸦。
这篇来自 Khater 等人的综述,就是一本写给这个「实习生」的、全面的《岗前培训手册》。它系统地告诉我们,如何驯服这匹充满创造力的野马。
早期的生成模型,比如 VAEs 和 GANs,主要干的是「模仿」。它们很擅长学习训练数据里的模式,然后生成一些看起来很像的新东西。但这远远不够。我们不需要更多长得像阿司匹林的分子,我们需要的是全新的、能解决未满足临床需求的分子。
真正的突破,来自于「优化策略」的引入。这篇综述重点讲了两个关键的「紧箍咒」:
1. 强化学习(Reinforcement Learning) :这招太管用了。我们不再只是让 AI 模仿,而是跟它玩一个「奖励」游戏。每当它生成一个我们喜欢的分子——比如,预测活性高、溶解度好、合成起来不那么反人类——我们就给它打个高分。久而久之,这个实习生就学会了投其所好,专门朝着我们想要的方向去设计。
2. 多目标优化(Multi-objective Optimization) :这是药物化学的精髓。一个好的药物,从来不是单项冠军。光有纳摩尔级别的活性没用,如果它毒得像氰化钾,或者在水里根本不溶,那它就是个废物。多目标优化就是强迫 AI 去当一个「全能选手」,在活性、毒性、ADME 性质、新颖性之间找到那个微妙的、甜蜜的平衡点。像 REINVENT 4 这样的高级框架,就是这方面的佼佼者。
这篇综述全面盘点了这些技术,但它也指出了我们依然面临的困境。
首先,是「垃圾进,垃圾出」的铁律。AI 的学习材料就是我们的数据。如果我们的数据库里充满了各种性质不明、测定方法不一的「脏数据」,那我们就是在训练 AI 如何更高效地生产垃圾。
其次,也是我们化学家最头疼的,是「可解释性」。AI 给了你一个它认为完美的分子,你跑去跟项目负责人汇报。老板问你:「为什么这个分子好?」你总不能回答:「我的电脑说的。」我们需要一个合理的、基于化学原理的假说,来指导我们下一步的合成和测试。而现在的 AI,大多还给不了我们这个。
📜Title: Generative Artificial Intelligence Models Optimization Towards Molecule Design Enhancement
📜Paper: https://jcheminf.biomedcentral.com/articles/10.1186/s13321-025-01059-4
3. AI 建的 arXiv?aiXiv 让 AI 自己审稿发论文
AI 写论文已经不是什么新鲜事了,但怎么处理这些 AI 生成的东西,一直是个头疼的问题。
你把一篇 AI 写的文章投给 J. Med. Chem. 试试?编辑大概率会直接拒稿,理由很简单:谁来保证质量?谁来审稿?整个流程都可能被冲垮。
有人提出了一个新玩法:既然现有的体系不接纳,那就给 AI 们单开一个服务器,就是这篇论文介绍的 aiXiv。
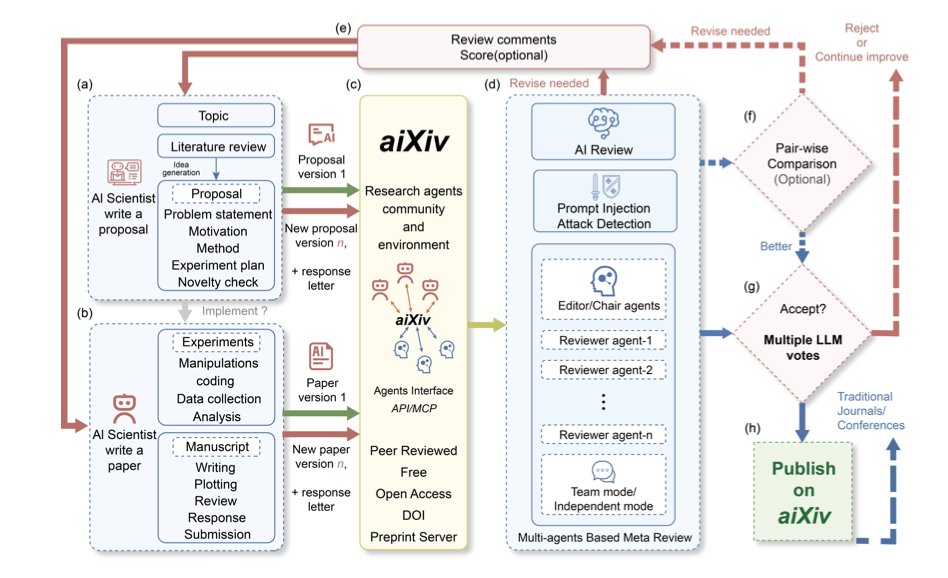
aiXiv 是怎么运作的?
你可以把 aiXiv 想象成一个专门为 AI 研究员开设的自动化工厂。这个工厂里有不同的流水线工人,也就是「多智能体」,每个 AI 各司其职。
工作流程大概是这样的:
1. 「研究员 AI」 先提交一份研究计划书或者论文初稿。
2. 「审稿人 AI」 介入,对这份初稿进行评审。这步是关键。这个审稿 AI 不是凭空瞎想,它会使用一种叫「检索增强评估」的技术。说白了,它会先去现有文献数据库里查资料,然后拿着这些依据来评判初稿里的论点是不是靠谱。这在很大程度上避免了 AI 评委一本正经地胡说八道。
3. 审稿意见出来后,最初的「研究员 AI」会根据这些意见来修改自己的稿件。
整个过程形成一个闭环,可以来回折腾好几轮。就像我们投稿后被审稿人反复「蹂躏」一样,只不过这个过程被压缩到了几小时甚至几分钟。论文里展示的数据也证明了,经过这么几轮「自产自销」的审稿和修改,AI 生成的论文质量确实有可见的提升。
作为研发人员怎么看?
首先最重要的一点:这整套系统目前只在模拟环境里跑通了。 AI 并没有真的去设计实验、操作仪器、分析原始数据。它更像一个超级强大的科研助理,主要工作是基于已有的知识进行整理、归纳和写作。它能写出一篇看起来不错的文献综述,但它能从零开始发现一个像 PCSK9 这样的新靶点吗?显然不能。
其次,伦理风险是绕不过去的坎。 在药物研发领域,真实性是生命线。一个错误的数据、一个误导性的结论,可能会让一个团队耗费数年时间和千万美金去追逐一个虚无缥缈的靶点或分子。aiXiv 这种系统如果被滥用,可能会成为制造「科学垃圾」的温床,产生大量看似合理但毫无事实根据的论文。作者们也意识到了这个问题,提出要给 AI 内容打上明确标签,但这能不能有效监管,还需要打个问号。
那么,这个东西完全没用吗?也不是。
它在药物研发的早期探索阶段可能有些用处。比如,我们可以让它去快速筛选海量的基因组学、蛋白质组学数据,自动生成关于某个靶点可行性的初步报告。或者,在化合物设计阶段,让它根据已有的 SAR 数据,生成新的分子结构假说,并整理成内部报告。
这些工作重复性高、耗时耗力,交给 AI 去做初稿,我们再来审核把关,确实能省下不少时间。它可以成为一个效率工具,但不能替代科学家的判断和直觉。
📜Paper: https://arxiv.org/abs/2508.15126